Weekly PR's Week 2: Dive into Android Architecture Guide
Hello There! Each week I try to write about the interesting stuff I dabble with whether it’s programming related or not, purely for self entertaintment purposes. Feedback is most welcome!
What this week is about ?
This week I finally had a chance to read the new Architecture Guide Google provided. I am late to the party as it is. But I thought It would be a good idea to summarize my thoughts about this guide here. So here we go.
Introduction
Structuring the Android application using a architectural pattern is not a new topic. MVC, MVP, MVVM, MVI, and Clean Architecture are some of the more well known patterns to structure the Android Code. Some applications may even contain 2 different types of architecture inside the codebase. Not all migrations happen gracefully.
Here, the application hierarchy is divided into 2 distinct layers with an optional additional layer if your business logic requires it. These are UI and Data layers, and optionally there is a Domain Layer.
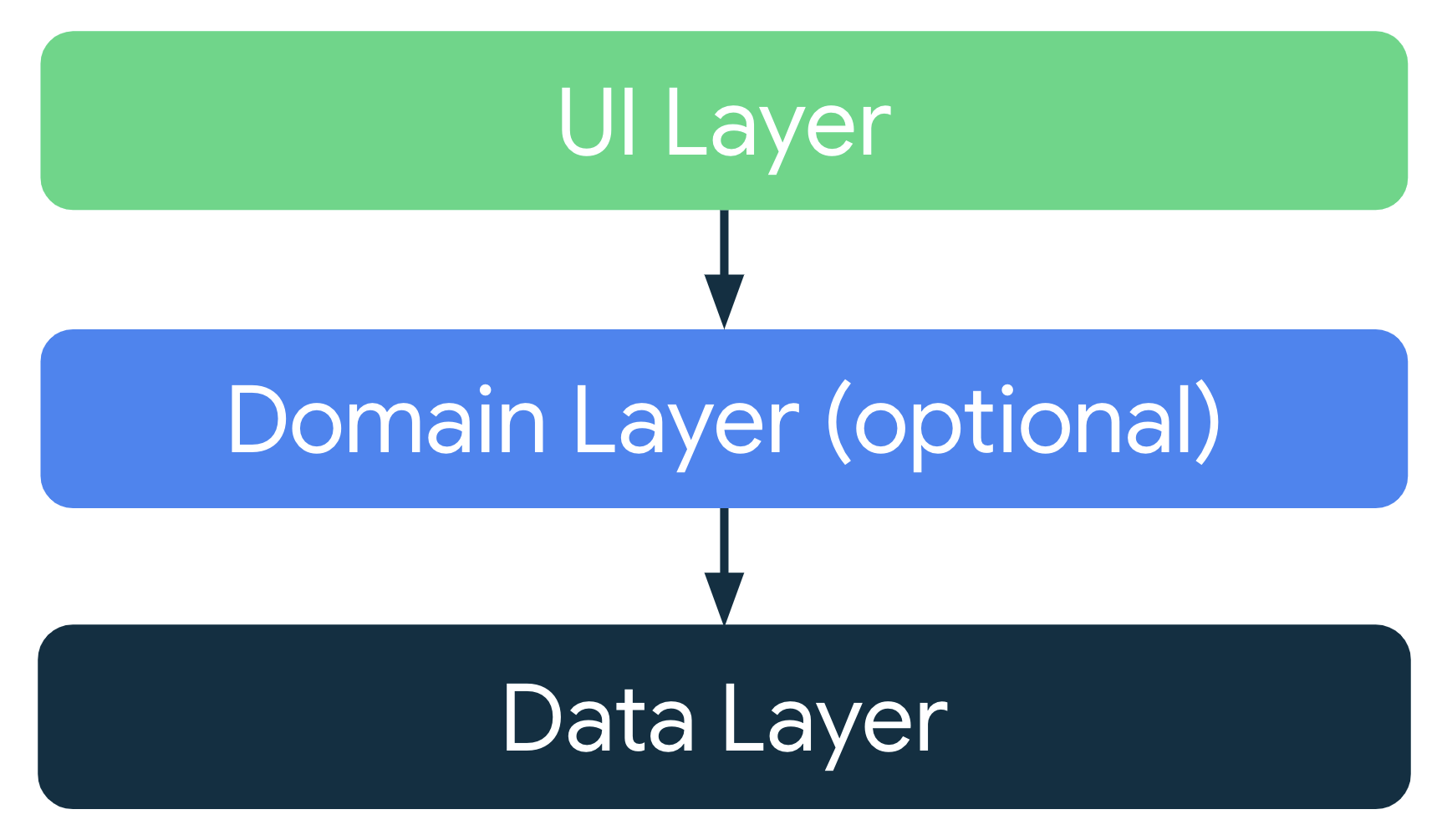
These layers provide a way to scale your application quickly with more robustness and ease of testability. But why is that necessary? The main reason is the Android Framework and Business Logic part of the App. More you couple your core logic with the Android Framework, more difficult testing, extending and reusing becomes.
What are these layers exactly ?
UI Layer is the primary point of user interaction and it is used to display the application data on the screen. It updates the state of the application based on external user events such as clicks, swipes and presses. It also registers the internal UI events that are triggered by the logic of the use cases and act accordingly.
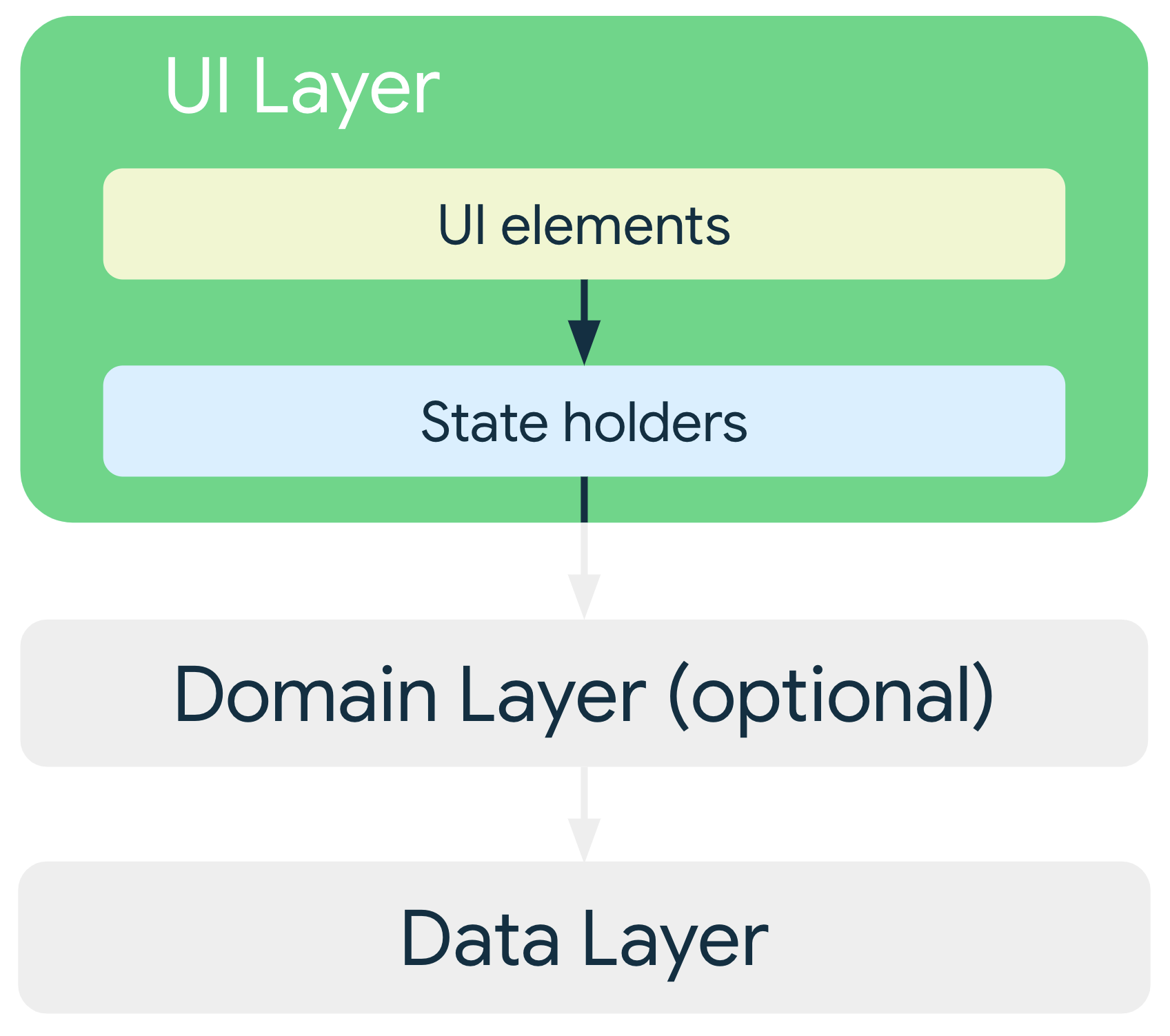
Data Layer is responsible for the application data and business logic. This layer offers components that can be used in multiple screens. Information can be shared between different parts of the app. The guide defines repository classes as the entry point for data access.
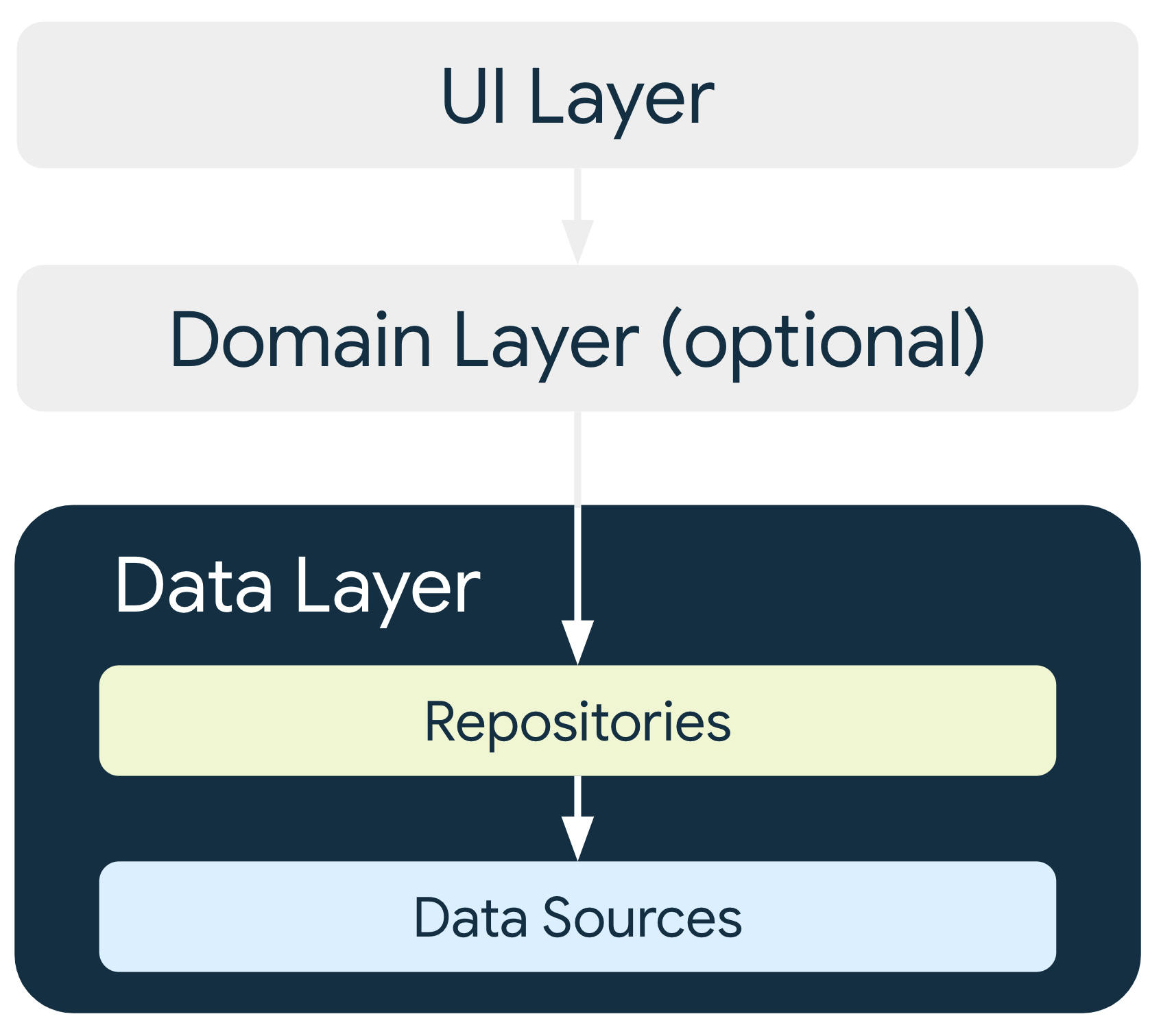
Each Repository might have zero to many Data Sources. Data Sources themselves should be responsible for only one source of data. So repositories use data sources to update or get the required data. They may manipulate the data using transformations and external input provided by the UI layer to get the final state of the data which will be shown to the user.
Domain Layer is the optional Business logic module that wraps the repositories and controls the business logic part that goes into the repositories. This module exists for mainly two reasons. To encapsulate complex business logic into a meaningful component, and provide simple business logic that can be reused to the different parts of the application.
How do Layers Communicate ?
Another point of this architecture is Driving UI from the Data. To eliminate edge cases between the screen states, defining the state of the app in point of time T and matching the screen state to the current data state can ensure that always correct information will be shown to the user. Also if the data is persisted, even if the OS kills the application, the correct UI state can be restored.
To manage the state changes, Unidirectional Data Flow pattern is used to build the communication between the layers. This patterns creates another separation between where the UI update is originated, where it is transformed and finally where it is consumed in the UI.
You can read more about this here
My Thoughts
Architecture presented is very similar to Clean Architecture. In fact, it might be the Clean Architecture in disguise. But it’s not a necessarily bad thing.
Some of the parts of the clean architecture can be interpreted in a different way. Over time, I’ve seen different implementations of Domain and Data Layers. Even defining them as Android Libraries or Pure Kotlin Modules changes the whole dependency structure of the project and creates different way of defining a data source or Repository.
I think keeping Data and Domain Modules in pure Kotlin and designing the repositories and data sources as interfaces provide the most flexiblity in terms of the Clean Code. Concrete implementation can reside in a separate Android Module. That way, Data and Domain module can become even more reusable across the application. I am thinking how this approach might be useful in a Kotlin Multiplatform project. A demo project to test this premise might be useful.
From the guide I can see that the main benefit of using it is the Separation of Concerns. From UI to the core part of the logic, each level of responsibility is abstracted away using a different layer. Separating the application into layers in my opinion is a must to make the development of new features more maintainable. However there are differents ways of enforcing it. One can define this layers in a module, or each feature module of the app can contain these layers as a directory. The choice of course depends, mainly to the projected complexity of the application.
That is it for this week. I tried to summarize some of the important parts of this guide from my perspective. If you want to read this guide in depth, and I suggest you to do it, you can do it from here. See you next week.
PS: For all images in this posts, credits: Android App Architecture Guide